Frequency-Based Shifts¶
Many word shifts can be constructed using only the frequency counts of how often words appear in each of two texts. The frequencies should be loaded into two dictionaries type2freq_1 and type2freq_2, where keys are word types and values indicate how many times that word appeared in that text.
Proportion Shifts¶
The easiest word shift graph that we can construct is a proportion shift. If \(p_i^{(1)}\) is the relative frequency of word \(i\) in the first text, and \(p_i^{(2)}\) is its relative frequency in the second text, then the proportion shift calculates their difference:
If the difference is positive (\(\delta p_i > 0\)), then the word is relatively more common in the second text. If it is negative (\(\delta p_i < 0\)), then it is relatively more common in the first text. We can rank words by this difference and plot them as a word shift graph.
proportion_shift = sh.ProportionShift(type2freq_1=type2freq_1,
type2freq_2=type2freq_2)
proportion_shift.get_shift_graph(system_names = ['L.B.J.', 'G.W.B.'],
title='Proportion Shift of Presidential Speeches')
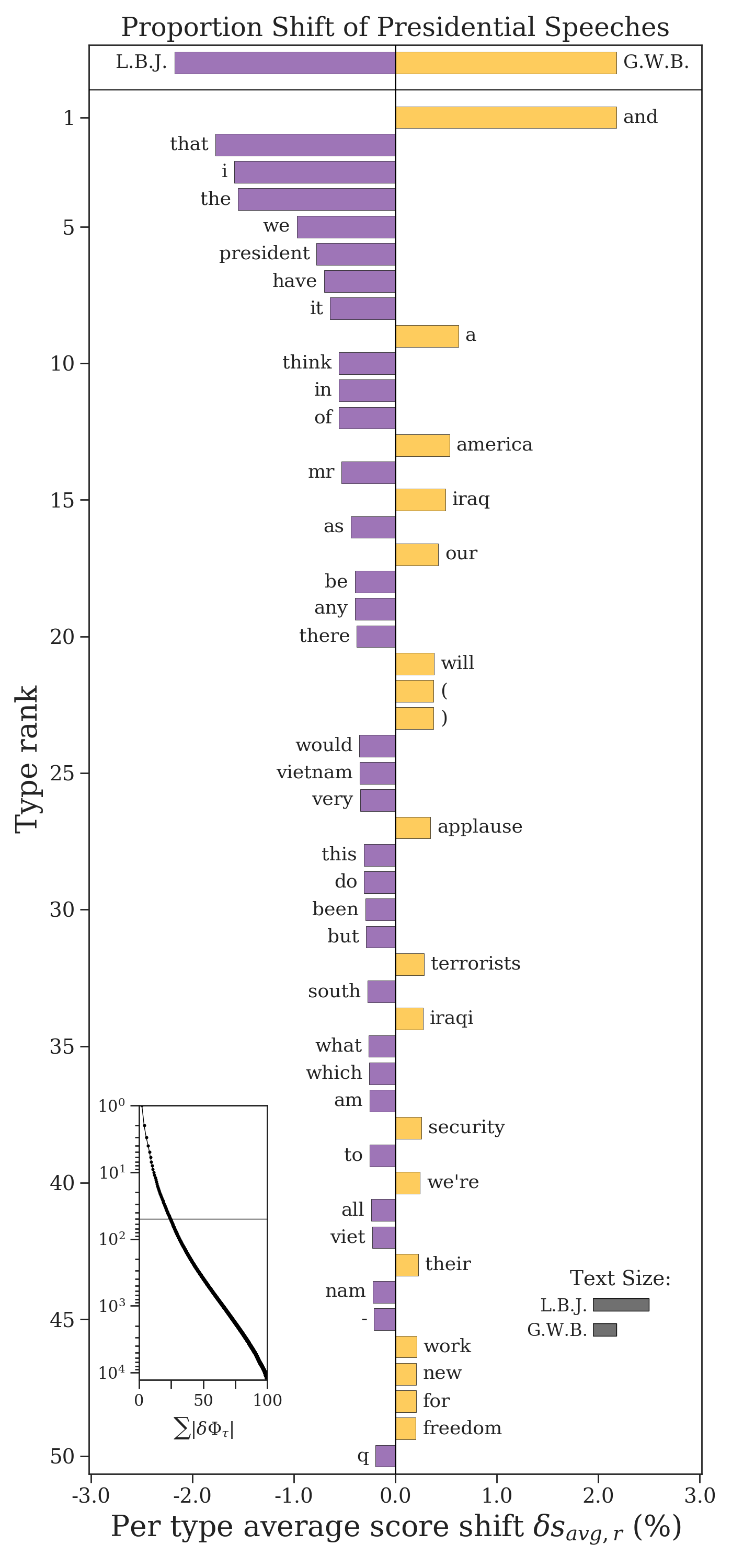
We see that, for example, Johnson used the word “vietnam” more than Bush, while Bush used the word “iraq” more than Johnson.
There are two diagnostic plots included in the bottom corners of the word shift plot.
- The first is the cumulative contribution plot, which traces how \(\sum_i |\delta p_i |\) changes as we add more words according to their rank. The horizontal line shows cutoff of the word contributions that are plotted versus those that are not. This helps show how much of the overal difference between the texts is explained by the top contributing words. In this plot, about a quarter of the overall difference is explained by the top 50 words.
- The second diagonstic plot shows the relative text size of each corpus, measured by the number of word tokens used. This plot tells us that the Johnson corpus is over twice as large as the Bush corpus (indeed, he made about twice as many speeches).
If we need the relative frequencies \(p_i^{(1)}\), they can be accessed through proportion_shift.type2p_1 and similarly for the second text. The differences \(\delta p_i\) are available in proportion_shift.type2shift_score.
Shannon Entropy Shifts¶
Proportion shifts are easy to interpret, but they are simplistic and have a difficult time pulling out interesting differences between two texts. For example, we see many “stop words” in the proportion shift. Instead, we can use the Shannon entropy to identify more “surprising” words and how they vary between two texts. The Shannon entropy \(H\) is calculated as
where the factor \(-\log p_i\) is the surprisal of a word. The less often a word appears in a text, the more surprising that it is. The Shannon entropy can be interpreted as the average surprisal of a text. We can compare two texts by taking the difference between their entropies, \(H(P^{(2)}) - H(P^{(1)})\). When we do this, we can get the contribution \(\delta H_i\) of each word to that difference:
We can rank these contributions and plot them as a Shannon entropy word shift. If the contribution \(\delta H_i\) is positive, then word \(i\) the has a higher score in the second text. If the contribution is negative, then its score is higher in the first text.
entropy_shift = sh.EntropyShift(type2freq_1=type2freq_1,
type2freq_2=type2freq_2,
base=2)
entropy_shift.get_shift_graph(system_names = ['L.B.J.', 'G.W.B.'])
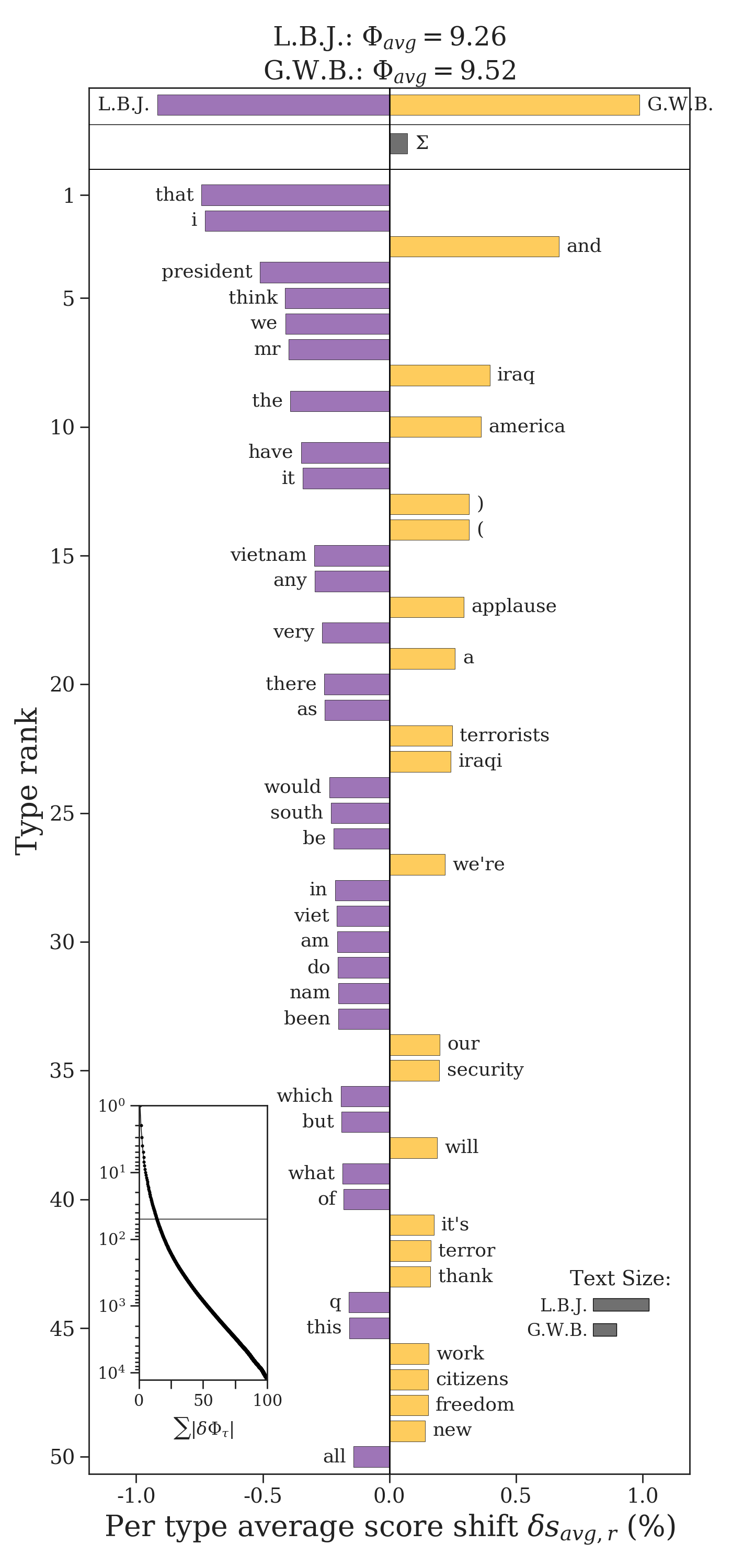
We now see some more interesting words differentiating Johnson’s and Bush’s speeches. The title of the word shift graph lists the entropy of president’s speeches. These entropies are also plotted relative to one another at the top of the plot, and the bar \(\Sigma\) shows the direction of their difference. By the title and \(\Sigma\), we see that Bush’s speeches are slightly more unpredictable. By the cumulative contribution inset in the bottom left hand corner of the word shift graph, we see that the top 50 words explain less 25% of the total difference in entropy between the two texts.
The contributions \(\delta H_i\) are available in entropy_shift.type2shift_score. The surprisals are available in entropy_shift.type2score_1 and entropy_shift.type2score_1 respectively.
Tsallis Entropy Shifts¶
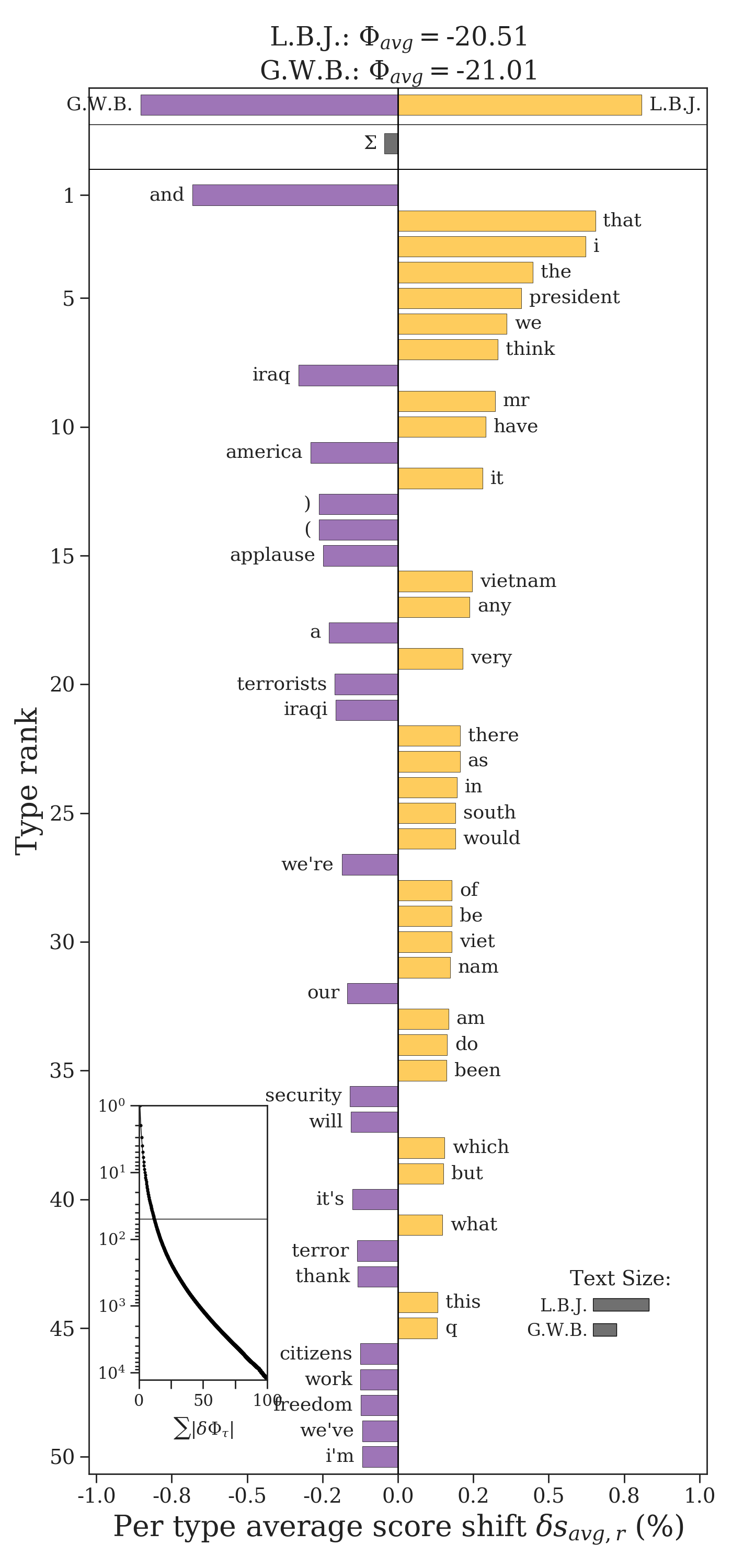
The Tsallis entropy is a generalization of the Shannon entropy which allows us to emphasize common or less common words by altering an order parameter \(\alpha > 0\). When \(\alpha < 1\), uncommon words are weighted more heavily, and when \(\alpha > 1\), common words are weighted more heavily. In the case where \(\alpha = 1\), the Tsallis entropy is equivalent to the Shannon entropy, which equally weights common and uncommon words.
The contribution \(\delta H_i^{\alpha}\) of a word to the difference in Tsallis entropy of two texts is given by
The Tsallis entropy can be calculated using EntropyShift by passing it the parameter alpha.
entropy_shift = sh.EntropyShift(type2freq_1=type2freq_1,
type2freq_2=type2freq_2,
base=2,
alpha=0.8)
entropy_shift.get_shift_graph(system_names = ['L.B.J.', 'G.W.B.'])
Kullback-Leibler Divergence Shifts¶
The Kullback-Leibler divergence (KLD) is a useful asymmetric measure of how two texts differ. One text is the reference text and the other is the comparison text. If we let type2freq_1 be the reference text and type2freq_2 be the comparison text, then we can calculate the KLD as
A word’s contribution can be written as the difference in surprisals between the reference and comparison text, similar to the Shannon entropy except weighting each surprisal by the frequency of the word in the comparison.
The contribution is positive if \(p_i^{(2)} > p_i^{(1)}\). Similarly, it is negative if \(p_i^{(2)} < p_i^{(1)}\).
Warning
The KLD is only well-defined if every single word in the comparison text is also in the reference text. If \(p_i^{(2)} > 0\) and \(p_i^{(1)} = 0\) for even a single word \(i\), then the KLD diverges to infinity.
The KLD is easily called from shifterator.
kld_shift = sh.KLDivergenceShift(type2freq_1=type2freq_1,
type2freq_2=type2freq_2,
base=2)
kld_shift.get_shift_graph()
The total Kullback-Leibler divergence be accessed through kld_shift.diff.
Jensen-Shannon Divergence Shifts¶
The Jensen-Shannon divergence (JSD) accounts for some of the pathologies of the KLD. It does so by first creating a mixture text \(M\),
where \(\pi_1\) and \(\pi_2\) are weights on the mixture between the two corpora. The JSD is then calculated as the average KLD of each text from the mixture text,
If the probability of a word in the mixture text is \(m_i = \pi_1 p_i^{(1)} + \pi_2 p_i^{(2)}\), then an individual word’s contribution to the JSD can be written as
Note
The JSD is well-defined for every word because the KLD is taken with respect to the mixture text \(M\), which contains every word from both texts by design. Unlike the other measures, a word’s JSD contribution is always positive, so we direct it in the word shift graph depending on the text in which it has the highest relative frequency. A word’s contribution is zero if and only if \(p_i^{(1)} = p_i^{(2)}\).
Like the Shannon entropy, the JSD can be generalized using the Tsallis entropy and the order can be set through the parameter alpha.
jsd_shift = sh.JSDivergenceShift(type2freq_1=type2freq_1,
type2freq_2=type2freq_2,
weight_1=0.5,
weight_2=0.5,
base=2,
alpha=1)
jsd_shift.get_shift_graph(system_names = ['L.B.J.', 'G.W.B.'],
title='JSD Shift of Presidential Speeches')
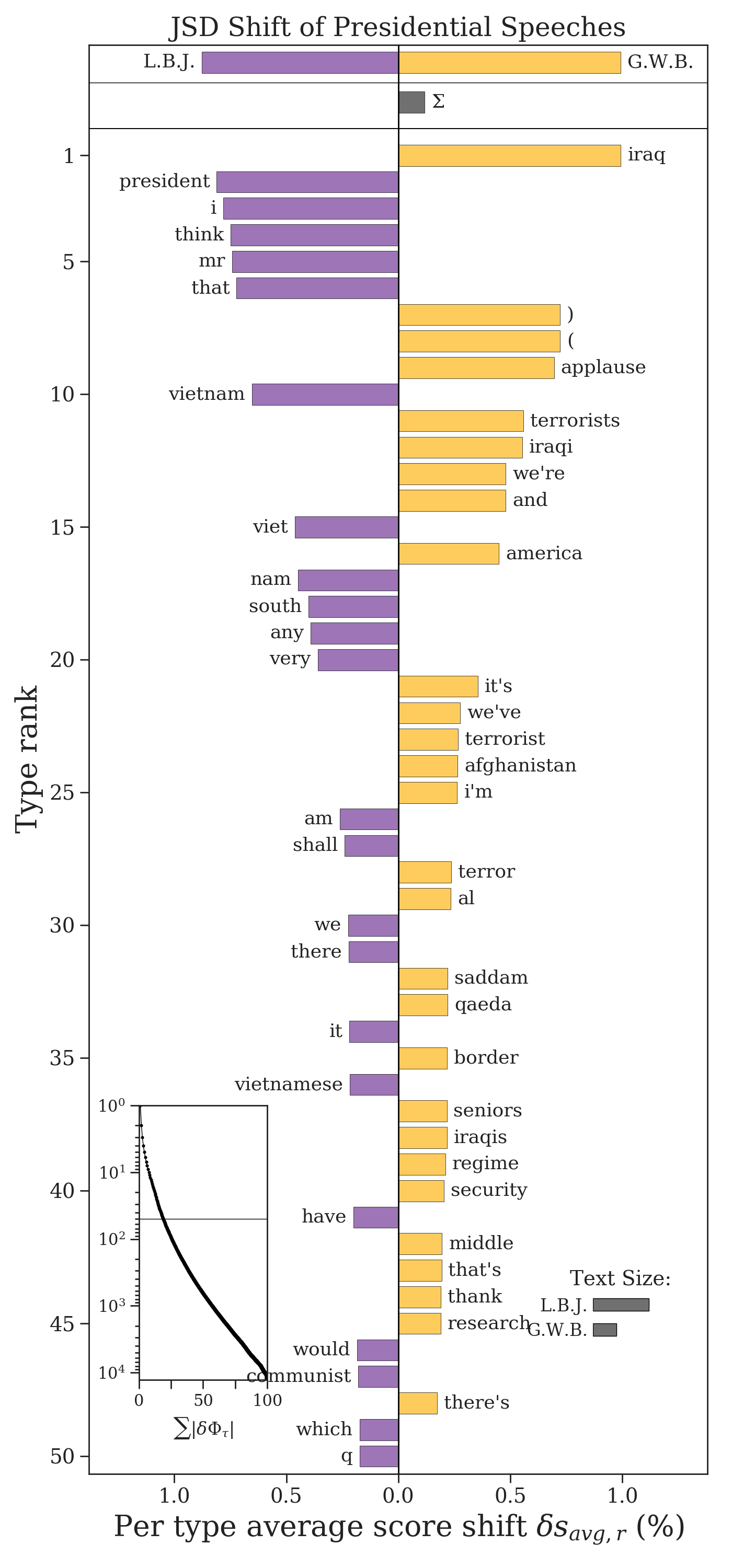
Quite often the JSD is effective at pulling out distinct words from each corpus (rather than “stop words”), but it is a more complex measure and so it is harder to properly interpret it as a whole.
The total Jensen-Shannon divergence be accessed through jsd_shift.diff.